Preface: In standard TCP/IP networking, the CPU is the bottleneck. Every packet must be copied from the NIC buffer to the Kernel buffer, then to the Application buffer. This "Buffer Copy Tax" adds latency and burns CPU cycles. RDMA (Remote Direct Memory Access) eliminates the taxman.
1. RDMA: Zero Copy Networking
Imagine sending a package to your neighbor.
TCP/IP: You hand it to a courier, who takes it to a sorting center, who hands it to
a delivery driver, who hands it to your neighbor's receptionist.
RDMA: You teleport the package directly onto your neighbor's desk.

By bypassing the Kernel (OS), we achieve:
- Ultra-Low Latency: <1 microsecond (vs 20-50us for TCP).
- Zero CPU Load: The CPU is free to compute Gradients (AI), not move packets.
- High Bandwidth: Linear scaling to 400Gbps/800Gbps.
2. The Doorbell Mechanism
If the Kernel isn't involved, how does the NIC know there is data to send? The CPU writes a "Work Queue Element" (WQE) to a memory address mapped to the NIC and "rings a doorbell" (sends a signal). The NIC then fetches the data via DMA (Direct Memory Access) and ships it.
3. RoCE v2 Packet Anatomy
InfiniBand (IB) was the original protocol for RDMA. But IB cables are expensive and niche. RoCE (RDMA over Converged Ethernet) allows us to run the InfiniBand protocol over standard Ethernet/IP networks.
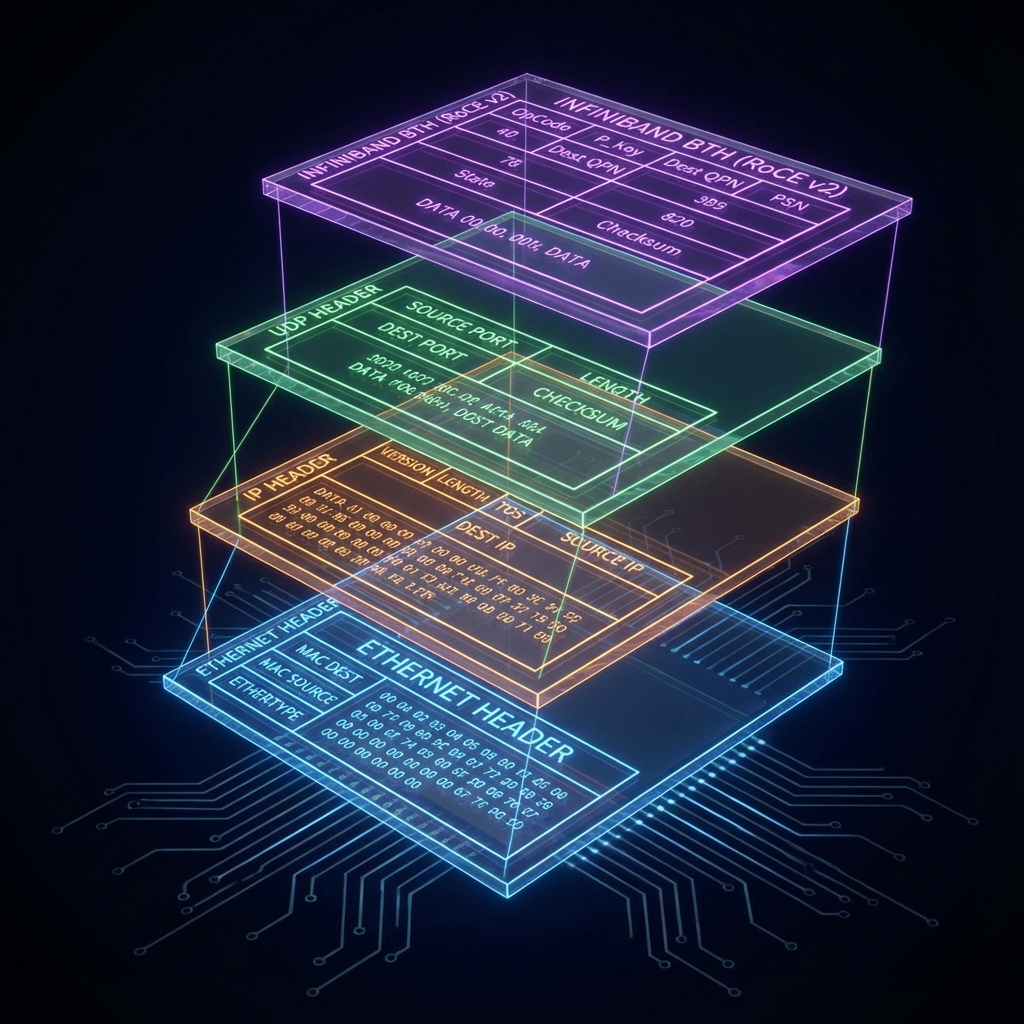
The Layers:
- Ethernet: Physical transport (MAC Addresses).
- IP (Internet Protocol): Routing (IP Addresses).
- UDP (User Datagram Protocol): Dest Port 4791 identifies this as RoCE. This allows ECMP (Equal-Cost Multi-Path) load balancing across the fabric.
- IB BTH (Base Transport Header): Contains the specific memory addresses and queue pair numbers for the RDMA transaction.
4. Lossless Ethernet (PFC)
RDMA assumes the connection is reliable. It does not have the sophisticated retransmission logic of TCP. If a packet is dropped, performance falls off a cliff.
To prevent drops, we use Priority Flow Control (PFC). If a switch buffer is 80% full, it screams "STOP!" (Pause Frame) to the upstream sender. The sender pauses instantly. This creates a "Lossless" fabric, but introduces the risk of "Head-of-Line Blocking" if a pause frame propagates too far.